Local representations
Extract normalized image patch embeddings and caption token embeddings instead of collapsing both modalities into one vector.
Reference-Free Image Caption Evaluation
MSD-Score evaluates image captions without references by modeling local visual evidence and token-level textual claims as distributions, then combining fine-grained discrepancy with global image-text similarity.
Abstract
Evaluating captions without references is difficult because global embedding similarity often misses hallucinated objects, missing attributes, or incorrect relations. MSD-Score models image patches and text tokens as von Mises-Fisher mixtures on the unit hypersphere. A weighted bi-directional KL divergence captures complementary coverage and support failures, while Soft-MSD adaptively combines this local discrepancy with global similarity. The result is a deterministic, decomposable, and reproducible signal for faithful offline caption evaluation.
What It Adds
MSD-Score checks whether image regions are covered and whether caption tokens are visually supported.
Motivation
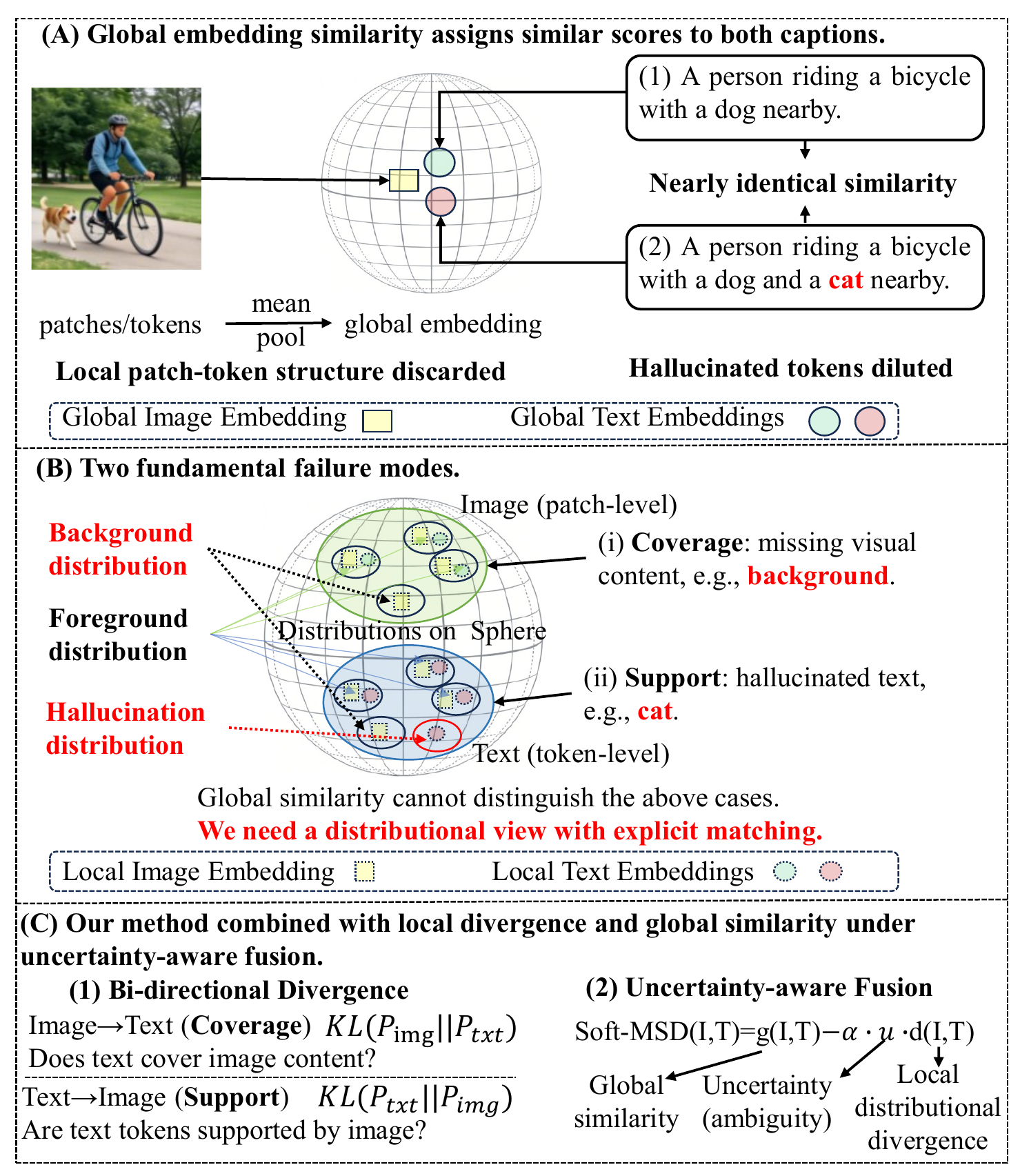
The central motivation of MSD-Score is that two captions can be globally similar to an image while differing in whether their token-level claims are visually grounded.
Method
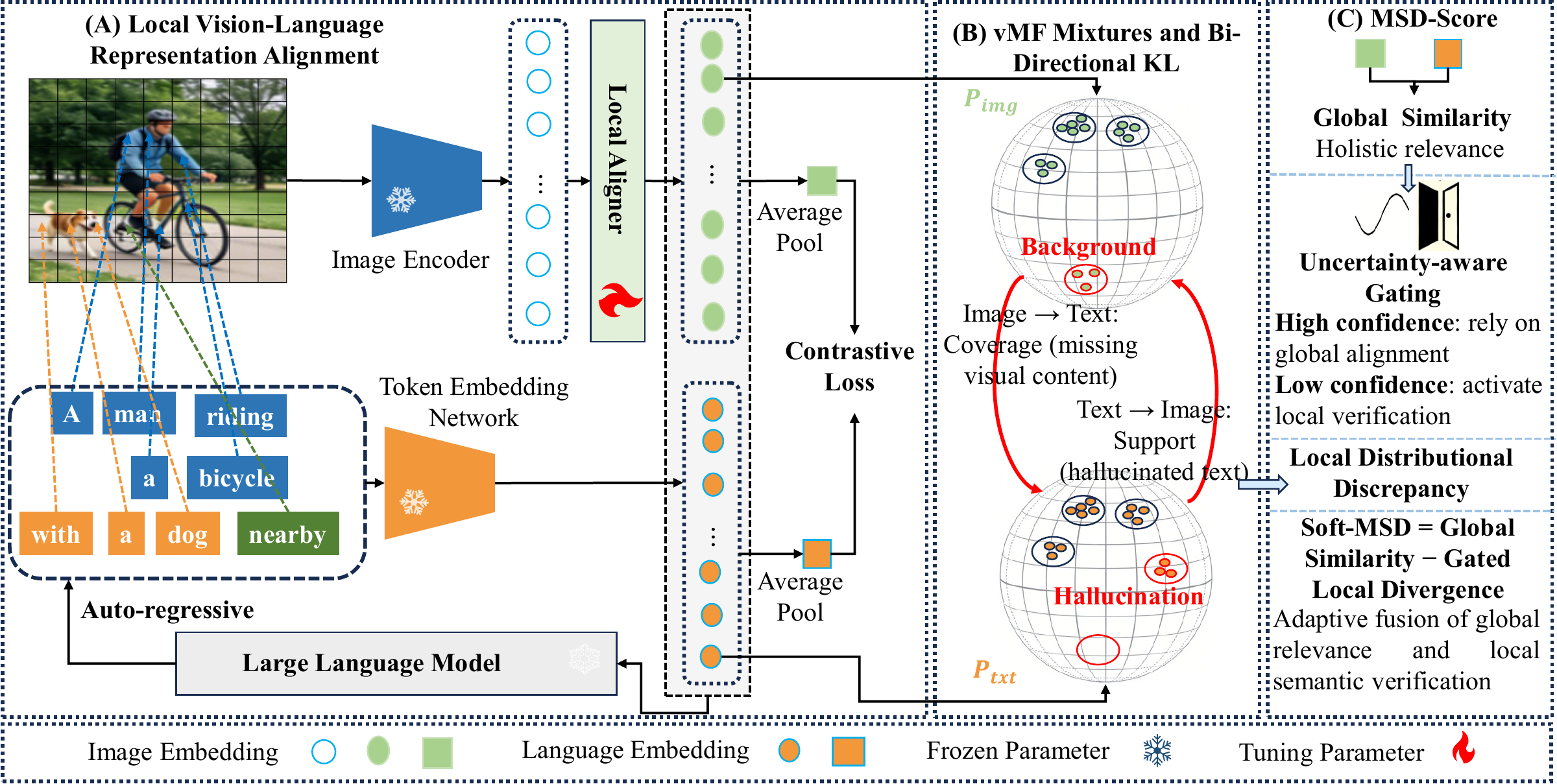
MSD-Score preserves local image-text structure and evaluates whether image regions and caption tokens agree at multiple scales.
Extract normalized image patch embeddings and caption token embeddings instead of collapsing both modalities into one vector.
Fit fixed-kappa hyperspherical mixtures to represent local semantic modes in high-dimensional, few-token regimes.
Use coverage and support divergences, then fuse local discrepancy with global similarity under uncertainty-aware weighting.
Results
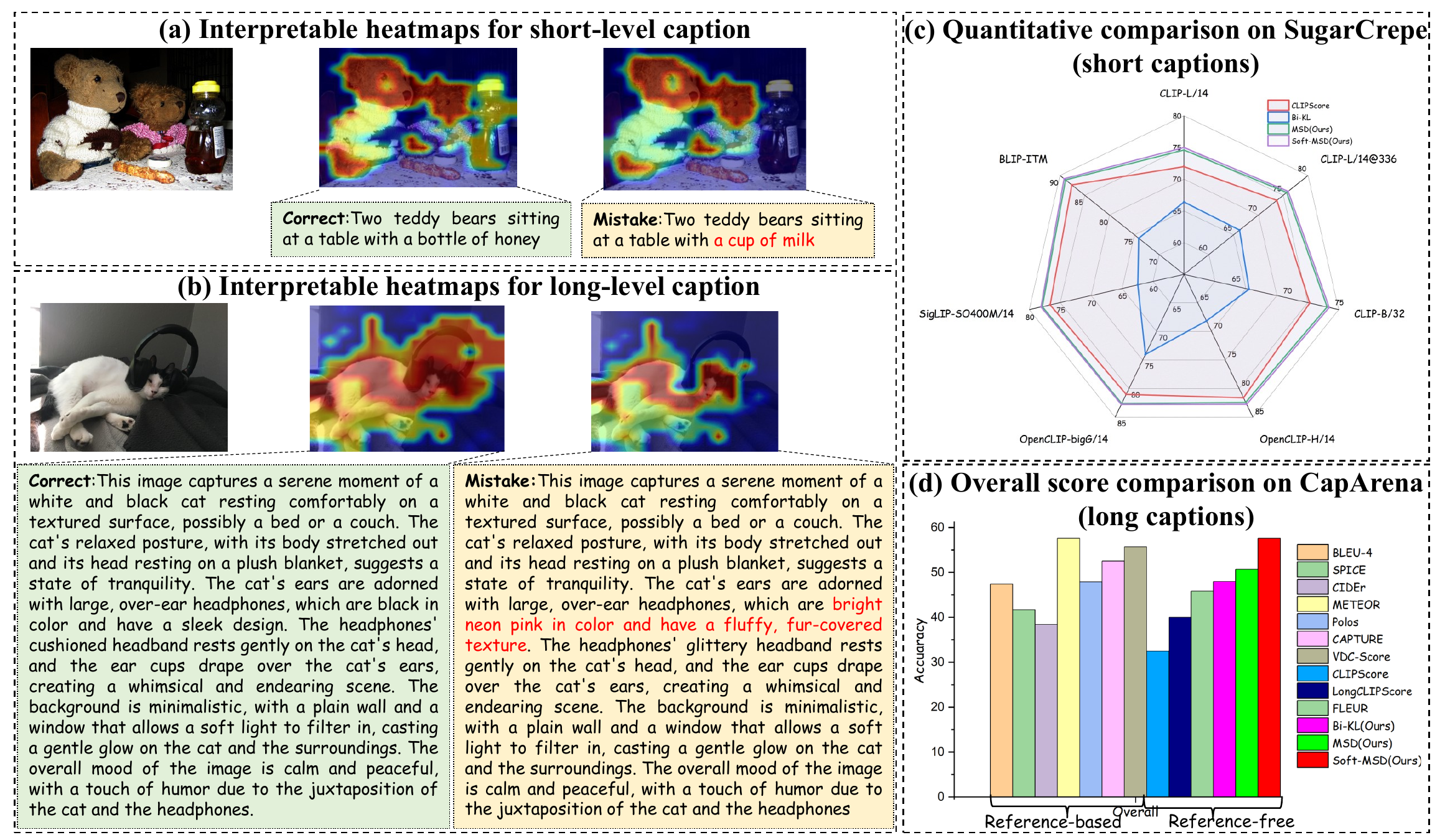
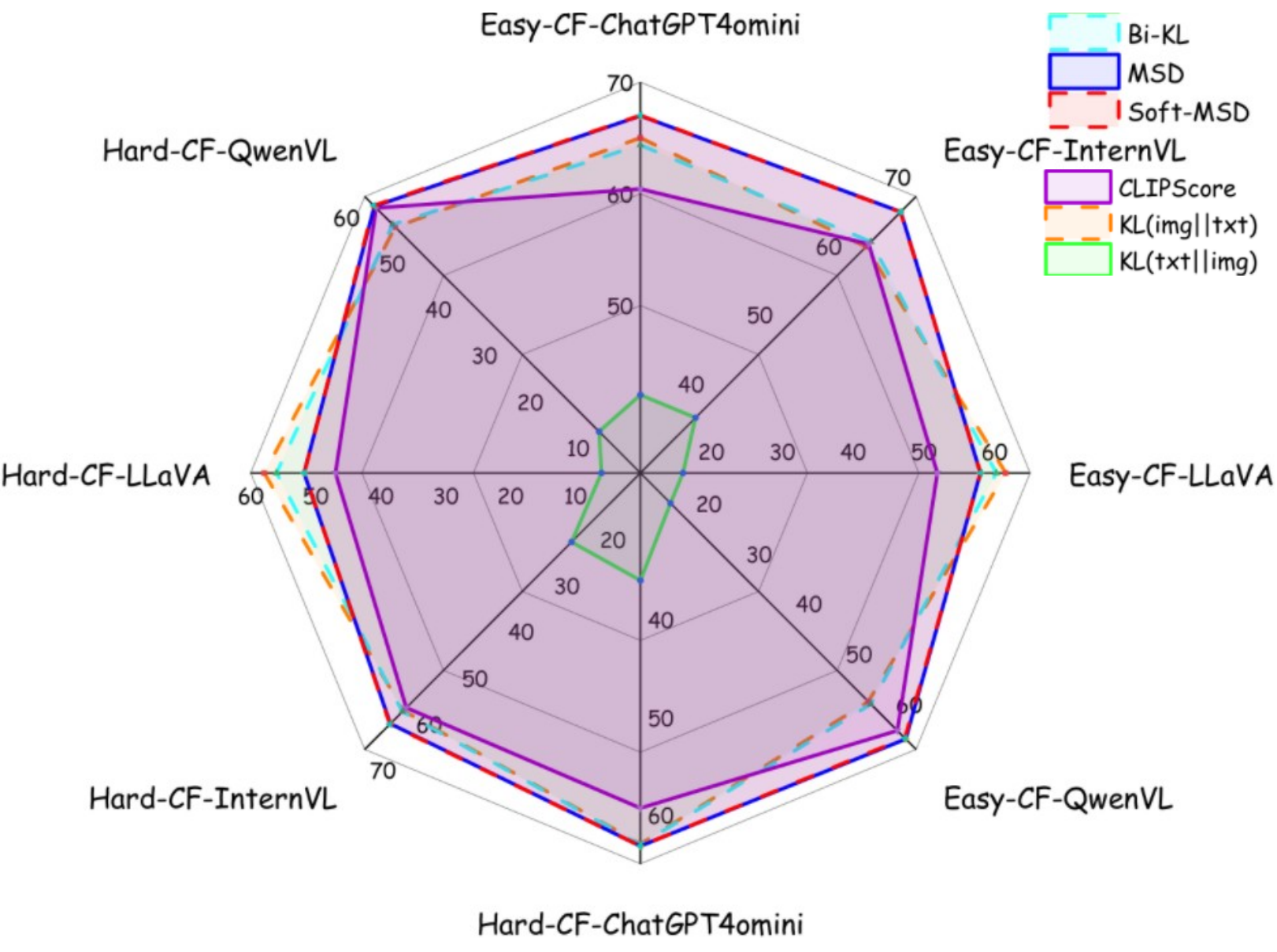
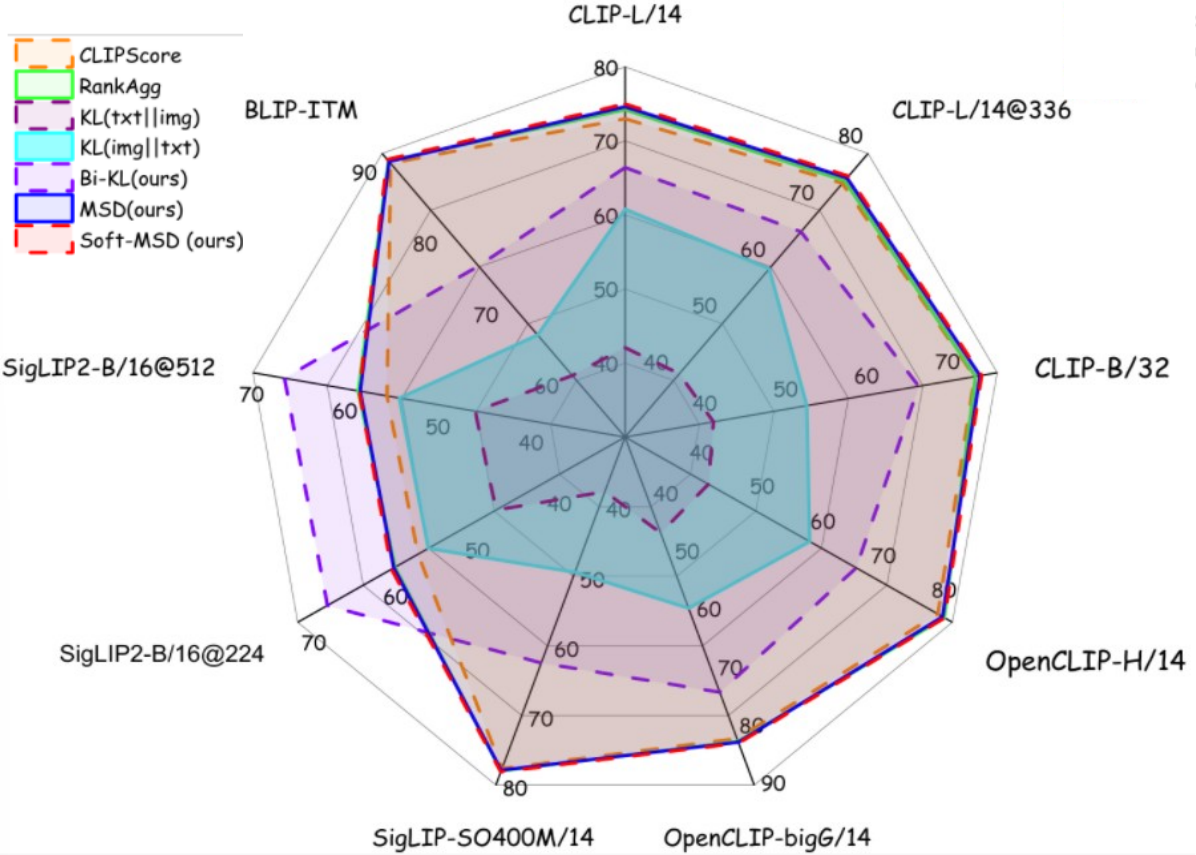
MSD-Score improves reference-free caption evaluation across human preference benchmarks, factual error datasets, and controlled counterfactual tests.
Diagnostics
The divergence can be decomposed into patch-level and token-level contributions, producing diagnostic heatmaps for unsupported details and missing visual evidence.

Citation
Use this BibTeX entry in papers, slides, benchmark reports, or project pages that reference MSD-Score.
@misc{kan2026msdscore,
title = {MSD-Score: Multi-Scale Distributional Scoring for Reference-Free Image Caption Evaluation},
author = {Kan, Shichao and Zhang, Xuyang and Zhang, Haojie and Zhu, Zhe and Cen, Yigang and Liang, Yixiong and Shan, Lianlei and Zhang, Linna and Qu, Zhe and Xia, Jiazhi},
year = {2026},
eprint = {2605.06080},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2605.06080}
}